| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- management
- Italy
- management and leadership
- Python
- hadoop
- RFID
- Java
- django
- web
- Linux
- Programming
- Book review
- comic agile
- MySQL
- Kuala Lumpur
- programming_book
- agile
- history
- Software Engineering
- UK
- erlang
- program
- leadership
- ubuntu
- Malaysia
- QT
- hbase
- Book
- France
- Spain
- Today
- Total
머신러닝 실무 프로젝트 본문

장점; 읽어보면 실무를 해본 사람들이 썼다는 걸 알 수 있다. 이론도 설명하지만, 실제 경험에서 오는 설명이 굉장히 와 닿는다
장점이자 단점; 책이 두껍지 않기 때문에 읽는데 부담이 좀 덜 하지만 자세한 내용을 원하는 경우 약간 부족하다는 생각이 들 수 있다
Part I
1장
특히 ‘1.2.2의 머신러닝을 사용하지 않는 방법 검토하기'가 인상적이다. 실무를 해본 사람들과 이야기해보면 흔히 하는 이야기지만, 출간하는 책에서 이렇게 쓰는 걸 보기는 힘들다. 사용하는 방법의 장점을 더 부각시켜야 독자가 흥미를 갖고 책을 읽지 않겠는가. 하지만 이렇게 솔직하게 현실을 썼다는 점에서 오히려 믿음이 갔다.
2장
머신러닝의 주제에 대한 대-소 분류 및 개념 설명을 하는데, 정말 정신없이 지나간다. 나 같이 어설프게 아는 사람에게는 다른 책에서 봤던 개념에 대한 설명 정도로만 이해하고 지나가게 될 거 같긴 하지만, 정리가 잘 되어 있어 읽기 편하다.
3장
평가를 위한 개념을 설명한다. 정밀도 정확도 재현률이나 TP, TN, FP, FN은 언제나 봐도 헷갈린다. 마이크로-매크로 평균이란 건 처음 봤고, RMSE와 결정 계수는 이름만 아는 정도인데, 일단 읽으면서 아~ 이랬지 하고 넘어갔다. 아마 또 잊어버려서 나중에 다시 봐야겠지.
4장
내용은 간단하지만, 실무에서 여러가지 경험을 통해 문제를 겪었다는 걸 느낄 수 있었다. 꼭 머신러닝이 아니더라도 시스템 구성의 기본적인 부분에 대해 궁금한 사람에게는 도움이 될 수 있다. 특히 로그에 대한 내용은 정말 공감이 간다. 간단한 프로그램이 아닌 이상 시스템에서는 로그를 남기고 쉽게 추적할 수 있어야, 문제가 생기건 개선을 하건 필요한 정보로 활용할 수 있는데, 대규모 로그를 잘 설계해서 사용하기 쉽게 만들면서도 필요한 정보를 즉각 보는 일은 정말 어렵다. 이런 면에서 참고할 만한 이야기가 많아 좋았다.
다만 아무리 봐도 그림 4–1, 2, 3이나, 5, 6, 7은 같은 그림으로 보이는데, 색을 다르게 했는데, 책에서는 흑백이라 구분이 가지 않는 건지 잘 모르겠다. 다시 봐도 똑같은 그림으로 보이는데.
5장
업무에 적합한, 질 좋은 데이터를 만드는 건 사실상 돈을 써야만 한다. 즉 수작업이 필요하다.
6장
가설 검정 부분은 통계를 몰라 그냥 그렇구나 하고 넘어갔으며, A/B 테스트 부분은 역시 동감한다.
Part II
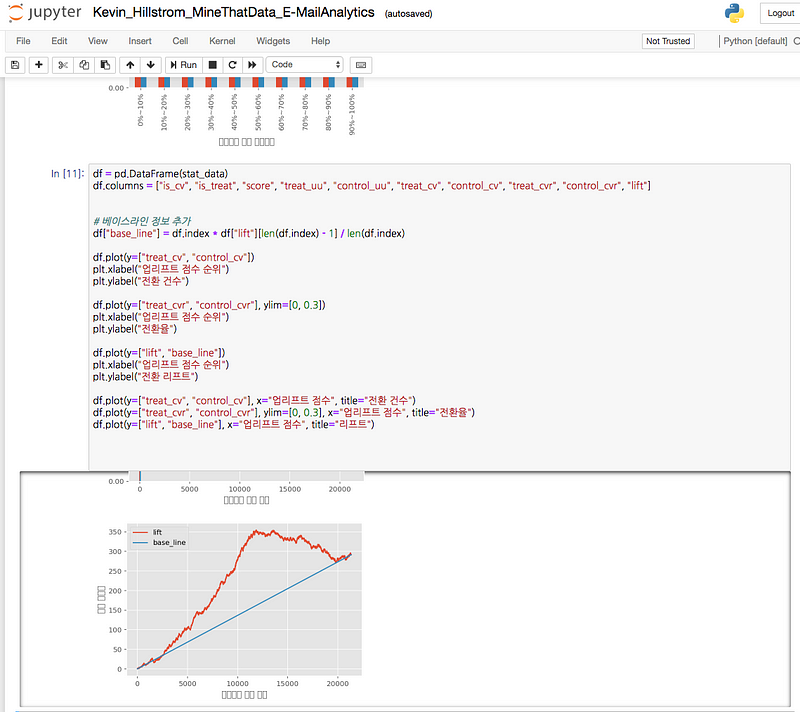
역자가 https://github.com/flourscent/ml-at-work 를 통해 잘 준비해둬서 따라하는 데 어려움이 없다. macbook에서 Anaconda Python 3.5.5로 실행했다.
설치
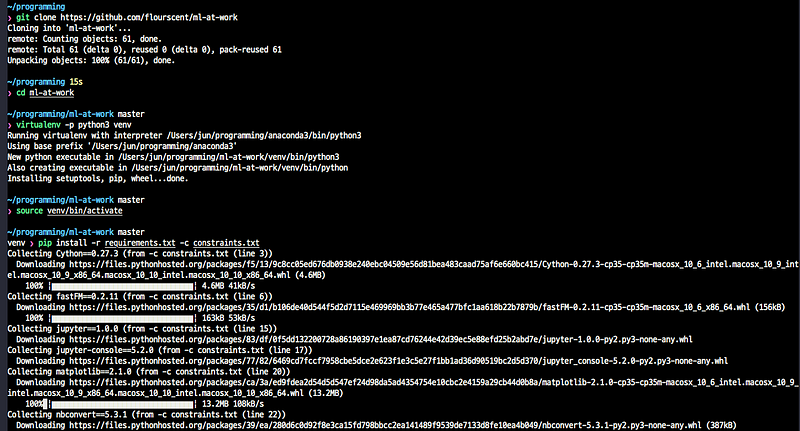
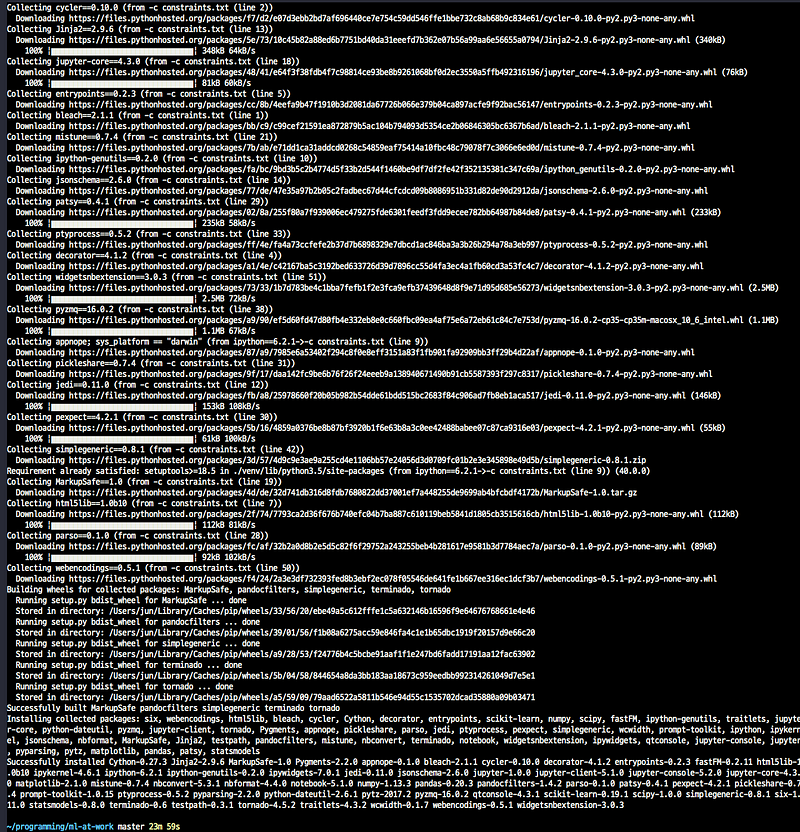
실행